|
|

|
AI BigLaw Bench subtask scores
| scholarship | 05/14/25 |
 Poast new message in this thread
Poast new message in this thread

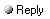
Date: May 14th, 2025 12:34 AM Author: scholarship https://www.harvey.ai/blog/expanding-harveys-model-offerings
“In less than a year, seven models (including three non-OAI models) now outperform the originally benchmarked Harvey system on BigLaw Bench,” Harvey wrote in the blog post. Harvey’s benchmark also showed that different foundation models are better at specific legal tasks than others. For instance, it says Google’s Gemini 2.5 Pro “excels” at legal drafting but “struggles” with pre-trial tasks like writing oral arguments because the model doesn’t fully understand “complex evidentiary rules like hearsay.” OpenAI’s o3 does such pre-trial tasks well, according to Harvey’s testing, with Anthropic’s Claude 3.7 Sonnet following close behind. |